
Claude Opus 4.7 深度评测:2026年编程智能体的性能天花板与隐形成本
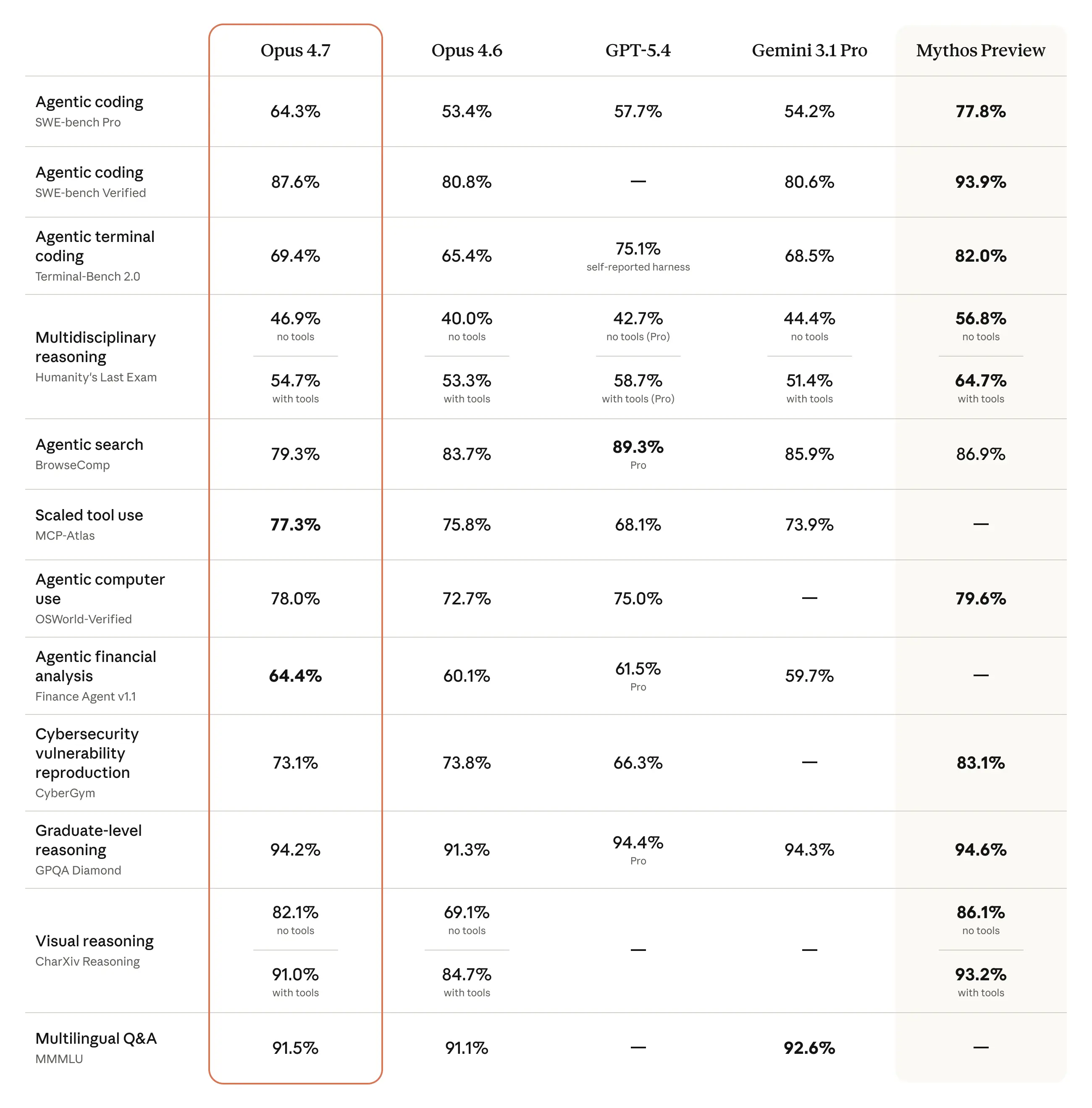
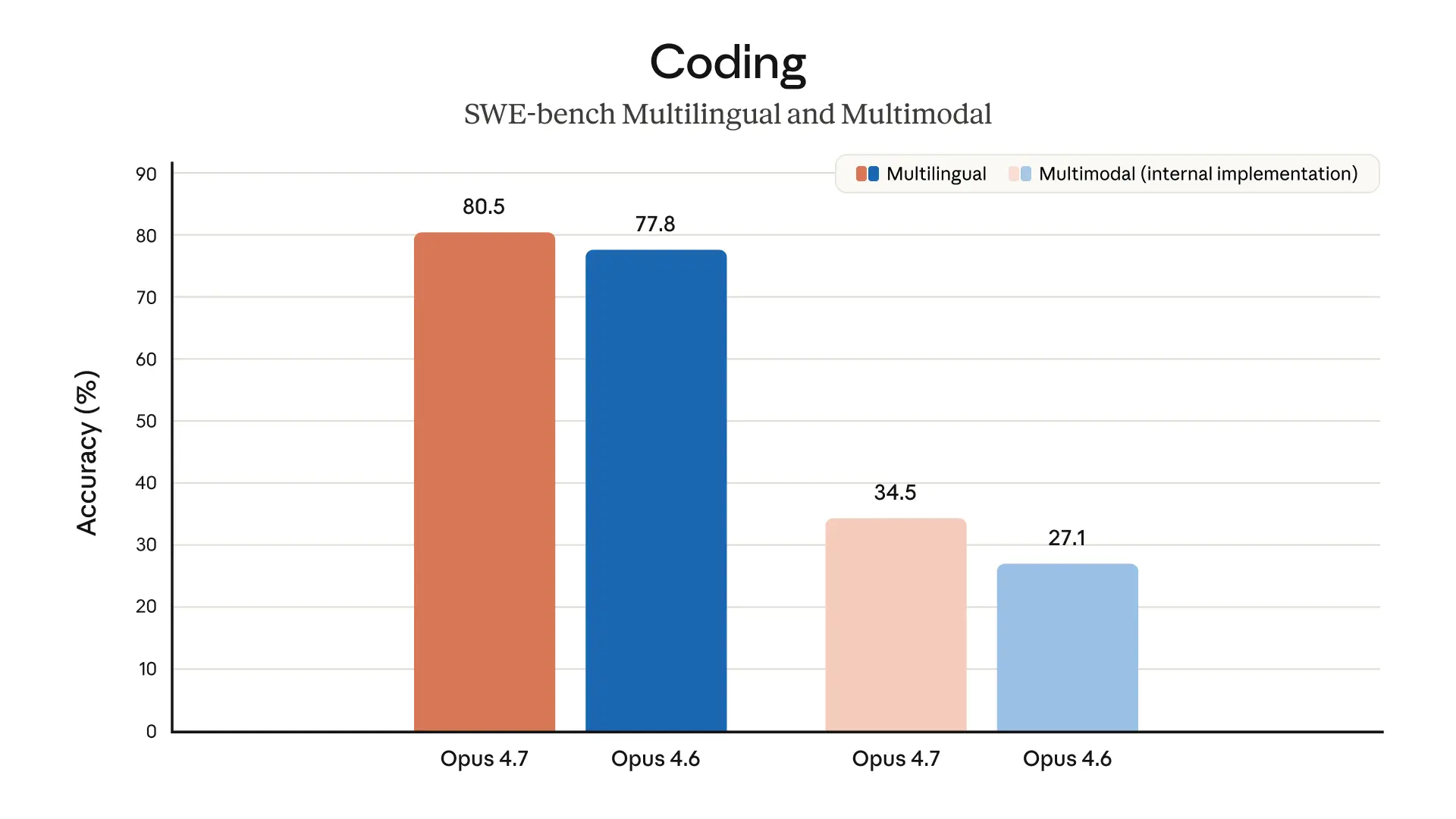
2026 年 4 月 16 日,Anthropic 正式发布了其目前最强大的一般可用模型(GA)——Claude Opus 4.7。这次更新不仅仅是一个小版本的迭代,它在软件工程基准测试中展现出了惊人的跨越,SWE-bench Verified 的得分从 80.8% 跃升至 87.6%,而 CursorBench 的评分也从 58% 提升到了 70%。
然而,在亮眼的成绩单背后,隐藏着一些需要开发者密切关注的细节:定价虽然未变,但“分词器(Tokenizer)”的重构可能让你的账单悄然上涨。本文将为你深度拆解 Claude Opus 4.7 的核心变化。

一、 编程智能体的四个关键进化
1. 编程基准测试的全面领跑
Claude Opus 4.7 在多项编程指标上刷新了纪录。Anthropic 官方及合作伙伴提供的评估数据显示:
- SWE-bench Verified: 87.6%(相比 Opus 4.6 提升了近 7 个百分点)。
- SWE-bench Pro: 64.3%,领先于 GPT-5.4 的 57.7%。
- CursorBench: 70%,这是由 Cursor CEO Michael Truell 确认的真实工作流评估。
CodeRabbit 报告称,在处理复杂 PR(拉取请求)时,Opus 4.7 的召回率提升了 10% 以上,且保持了稳定的精确度。这意味着它在处理大规模、跨文件的复杂代码库时,识别问题的能力变得更强。
2. “自我验证”:不再自信地犯错
这是 Opus 4.7 最显著的行为变化。模型现在会在声明任务完成之前,主动检查自己的产出。在编程场景下,这意味着它会自发地编写测试用例、运行测试并修复失败项,然后再将结果提交给编排层。
Notion AI 表示,它是第一个通过“隐性需求测试”的模型——即模型能够推断出必要的行动,而不是等待显式的工具调用指令。Hex 的 CTO 观察到,当数据缺失时,该模型能正确报告缺失,而不是提供看起来合理但错误的替代方案。

3. 新的努力水平:xhigh
Anthropic 在 low、medium、high 和 max 之间新增了 xhigh 档位。这是专为编程和智能体场景设计的默认档位。据 Hex 评估,Opus 4.7 的 low 档位性能已大致相当于 Opus 4.6 的 medium 档位。如果你追求极高任务质量,xhigh 是最佳平衡点。
4. 视觉能力的巨大跨越:3.75 MP 分辨率
最大图像分辨率从约 1.15 MP 提升至 3.75 MP(长边可达 2576 px),像素数量增加了 3.3 倍。在 XBOW 视觉精准度测试中,得分从 54.5% 飙升至 98.5%。 这意味着在执行“计算机使用(Computer Use)”任务时,模型识别的像素坐标可以与屏幕实际坐标 1:1 映射,不再需要繁琐的缩放校正。密集的架构图、扫描文档和复杂的 UI 界面现在都能被清晰识别。
二、 同价不同量的“陷阱”:分词器变化
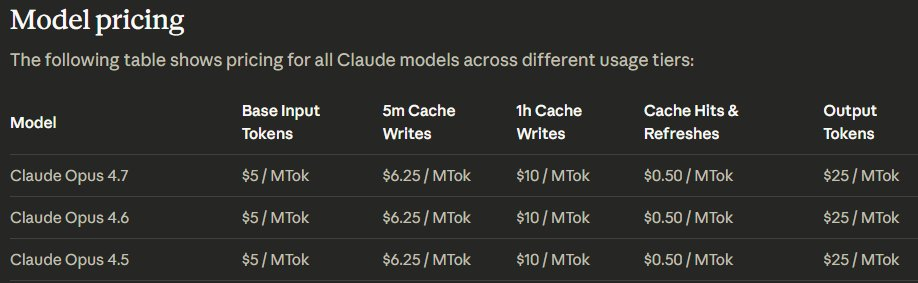
虽然 API 价格依然维持在每百万输入 Token $5 和每百万输出 Token $25,但 分词器(Tokenizer)的变化 改变了计费逻辑。新的分词器在处理相同文本时,生成的 Token 数量会增加约 1.0x 到 1.35x。
| 内容类型 | Token 增加趋势 | 备注 | | :--- | :--- | :--- | | 英语正文 | 低 (1.0–1.05x) | 聊天场景影响较小 | | 纯代码 | 中低 (1.05–1.1x) | 大多数 API 调用的常态 | | 结构化数据 (JSON/XML) | 中高 | 取决于模式的冗余度 | | 多语言文本 (CJK等) | 最高 (1.2–1.35x) | 中日韩用户成本上升最明显 |
这意味着,如果你在处理中文内容,即使单价没变,实际支出的成本可能上涨了 30% 以上。开发者需要通过 /v1/messages/count_tokens 重新核算生产环境的流量预算。
三、 并非全面碾压:Opus 4.7 的短板
虽然在纯编程领域表现卓越,但在某些垂直基准测试中,Opus 4.7 并非无懈可击:
- 终端操作 (Terminal-Bench 2.0): 得分 69.4%,仍落后于 GPT-5.4 的 75.1%。对于高度依赖 Shell 脚本和系统管理的智能体,GPT-5.4 依然有优势。
- 网页搜索与合成 (BrowseComp): 相比 Opus 4.6 出现了 4.4% 的回撤(83.7% -> 79.3%),而 GPT-5.4 Pro 和 Gemini 3.1 Pro 在此项上均领先于它。
四、 升级指南:你应该迁移吗?
如果你正在开发 AI 代码辅助工具或自主编程智能体,Opus 4.7 的升级几乎是必须的,因为它带来的自我验证能力和视觉精度提升能显著减少“幻觉”。
迁移注意事项:
- 分词器核算: 重新评估你的成本消耗,特别是多语言环境。
- API 变更: Opus 4.7 不再支持 Assistant 消息预填充(Prefilling),这会导致 400 错误,必须修改提示词结构。
- Mythos Preview: 记住,Opus 4.7 之上还有一个 Claude Mythos Preview。那是 Anthropic 目前最强的模型(Project Glasswing),但目前仅限于少数企业合作伙伴。如果你无法获取 Mythos,Opus 4.7 就是你能买到的最强性能。
结语
Claude Opus 4.7 的发布标志着 AI 编程从“单纯生成代码”向“具备自我审查能力的软件工程”转变。尽管在多语言成本和网页搜索上存在一些波动,但其在 SWE-bench 上的统治力证明了 Anthropic 在逻辑推理与复杂任务处理上的护城河。对于开发者而言,现在是时候切换 Model ID,体验这一新高度了。
本文数据参考自 Verdent Guides 及 PricePerToken 2026 年 4 月最新评测数据。