
编程智能体的新标准:Claude Opus 4.7 深度解析与实测指南
编程智能体的新标准:Claude Opus 4.7 深度解析与实测指南
2026 年 4 月 16 日,Anthropic 正式发布了其目前最强大的通用模型 Claude Opus 4.7。作为 Opus 4.6 的直接升级版,该模型在软件工程、视觉感知和智能体(Agent)协作方面展现出了令人瞩目的进步。然而,在这些光鲜亮丽的基准测试数据背后,一些关于成本和特定领域性能的变动同样值得每一位开发者关注。

1. 编程能力的质变:从“能写代码”到“能解决问题”
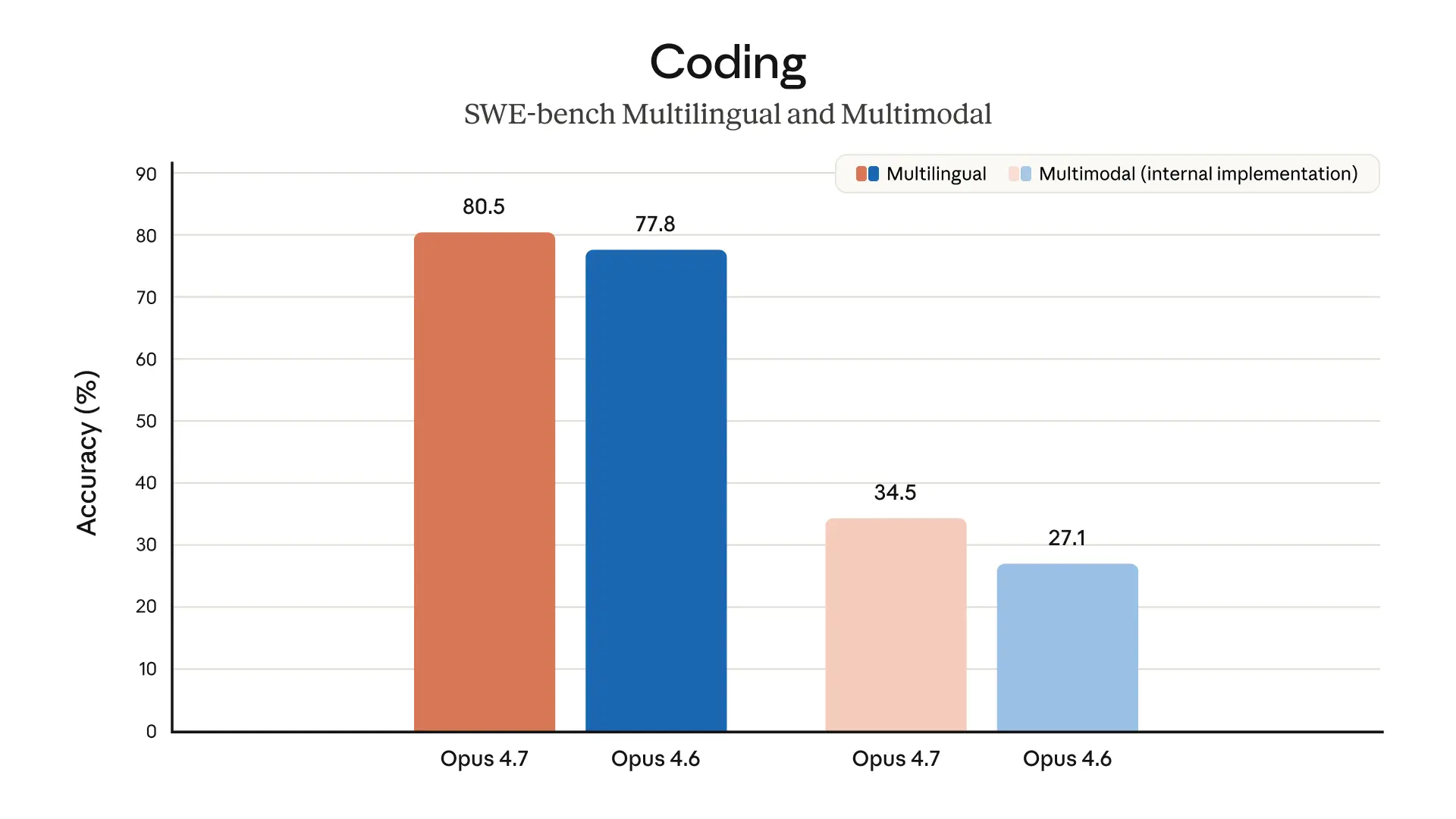
Claude Opus 4.7 最核心的提升在于其对复杂软件工程任务的处理能力。在衡量 AI 解决真实 GitHub 问题能力的 SWE-bench Verified 测试中,Opus 4.7 的得分从 4.6 版本的 80.8% 飙升至 87.6%。此外,由 Cursor 团队进行的 CursorBench 测试显示,其得分也从 58% 提升到了 70%。
自我验证机制(Self-verification)
与以往模型单纯生成代码不同,Opus 4.7 引入了主动验证行为。在智能体工作流中,该模型现在能够:
- 在交付结果前自行编写并运行测试。
- 自动修复测试失败的问题。
- 识别“隐含需求”。根据 Notion AI 的反馈,它是第一个能够通过“隐含需求测试”的模型,即在没有明确指令的情况下,能推断出必须执行的工具调用。
这种行为的转变显著降低了编程智能体输出“自信的错误结果”的概率。
2. 视觉升级:3.3 倍的分辨率飞跃
Opus 4.7 在视觉处理能力上取得了显著突破。最大图像分辨率从之前的 115 万像素提升到了 375 万像素(长边可达 2576 px)。
这一升级带来的实际应用优势包括:
- 1:1 坐标映射:在执行“计算机使用(Computer Use)”任务时,像素坐标现在可以直接映射到屏幕实际坐标,不再需要 Opus 4.6 那样的缩放转换步骤。
- 高精度识别:在 XBOW 视觉精准度基准测试中,Opus 4.7 的得分从 54.5% 跃升至 98.5%,能够轻松应对密集的屏幕截图、技术图表和扫描文档。
3. 性能基准:与 GPT-5.4 的强强对话
虽然 Opus 4.7 在多项测试中处于领先地位,但在特定领域仍面临激烈竞争。根据最新数据对比:
| 基准测试 | Opus 4.6 | Opus 4.7 | GPT-5.4 | 备注 | | :--- | :--- | :--- | :--- | :--- | | SWE-bench Verified | 80.8% | 87.6% | - | Anthropic 官方数据 | | Terminal-Bench 2.0 | - | 69.4% | 75.1% | 命令行任务执行,GPT 领先 | | BrowseComp | 83.7% | 79.3% | 89.3% | Web 研究任务,Opus 4.7 略有退步 | | GPQA Diamond | 91.3% | 94.2% | 94.4% | 前沿推理能力基本持平 |
需要注意的是,尽管 Opus 4.7 非常强大,但它仍略逊于 Anthropic 尚未全面公开的 Claude Mythos Preview(Project Glasswing 项目的一部分)。
4. 成本警示:相同的价格,不同的分词器
这是开发者最需要关注的部分。尽管 Opus 4.7 的 API 定价维持在输入 $5/M token 和输出 $25/M token,但 Tokenizer(分词器)发生了变动。
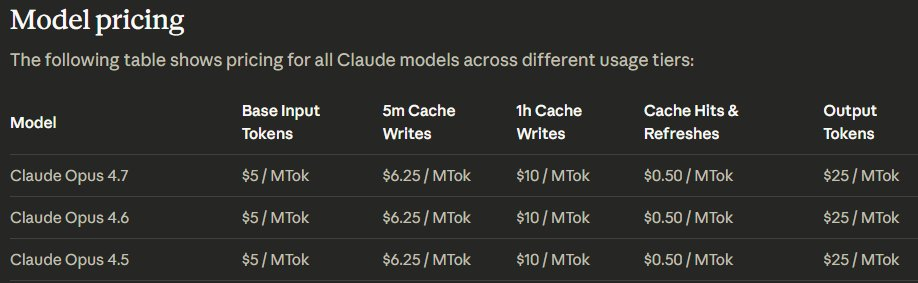
新版分词器对于相同的一段文本,生成的 token 数量会增加 1.0x 到 1.35x。这意味着:
- 英语散文:影响较小(~1.05x)。
- 多语言文本(包括中文、日文):可能增加 20%-35% 的 token 消耗。
- 结构化数据(JSON/XML):token 数量会显著增加。
由于每 token 单价没变,但总 token 数增加了,因此你的实际账单可能会增加 35%。在迁移生产环境前,建议务必使用 /v1/messages/count_tokens 重新核算成本。
5. 开发者建议:如何玩转新特性?
新的“努力水平(Effort Level)”
Opus 4.7 引入了 xhigh 努力级别,介于 high 和 max 之间。Anthropic 建议在编程和智能体场景中首选 xhigh。同时,新版本支持**任务预算(Task Budgets)**功能,允许开发者为整个智能体循环设置 token 目标。
迁移注意事项
- 移除 Prefill:Opus 4.7 不再支持 Assistant 消息预填(Prefilling),这会导致 400 错误,迁移前需修改提示词结构。
- 图像下采样:由于分辨率更高意味着 token 消耗更多,如果任务对精度要求不高,建议在上传前对截图进行下采样以节省费用。
- 最大 Token 设置:由于模型在
xhigh模式下“思考”得更多,建议将max_tokens设置在 64K 以上。
总结
Claude Opus 4.7 是编程智能体领域的一次重大升级,其强大的自我验证能力和卓越的视觉精度,使其成为当前开发者可用的最强一般可用(GA)模型。虽然分词器的变动变相增加了成本,且在 Web 研究方面略有回落,但对于追求极致编程效率和自动化的团队来说,这无疑是目前的不二之选。
