
RTX 加速 Gemma 4 与 AI Agent 崛起:开启本地智能与开发效率新纪元
随着人工智能技术的飞速发展,开源模型正引领着新一轮的设备端 AI 浪潮。从云端到本地设备的创新转移,不仅提升了隐私性,更让 AI 能够访问实时、本地的语境,从而将深刻的洞察转化为实际行动。近日,Google 发布的 Gemma 4 系列模型与 NVIDIA RTX 技术的深度结合,以及企业在开发流程中对 AI Agent 的成功应用,共同揭示了智能生产力的下一个巅峰。
Gemma 4:针对 NVIDIA GPU 优化的全能模型
Google 最新推出的 Gemma 4 家族包含了从轻量级的 E2B、E4B 到高性能的 26B 和 31B 多种版本。这些模型旨在实现从边缘设备到高性能 GPU 的高效部署。通过与 NVIDIA 的紧密合作,Gemma 4 在 NVIDIA RTX PC、工作站以及 DGX Spark 个人 AI 超级计算机上展现出了卓越的性能。
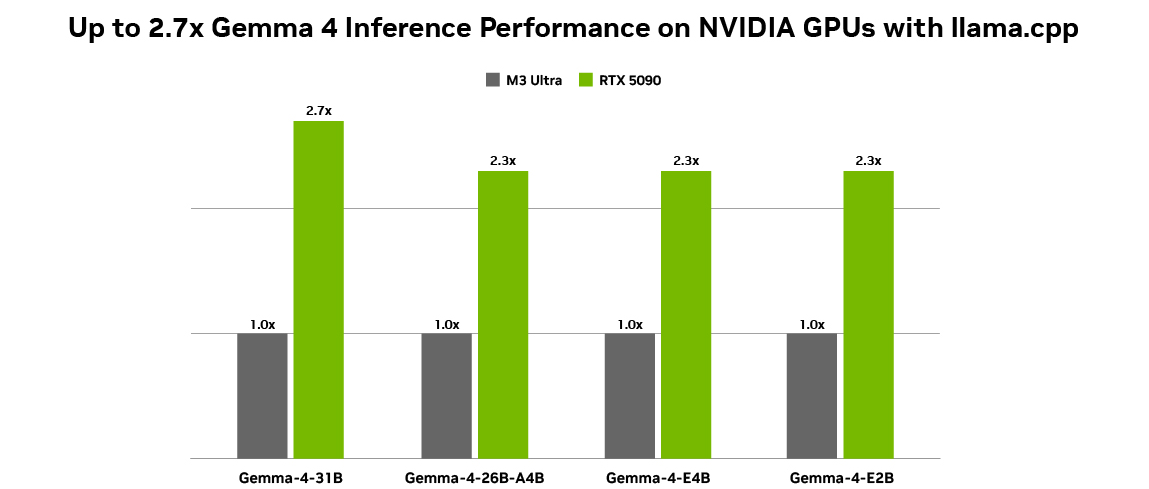
Gemma 4 的核心优势包括:
- 推理与编程能力:在处理复杂问题解决任务和代码生成、调试方面表现强劲。
- 原生支持 Agent:具备结构化工具使用(函数调用)能力,是构建智能体 AI 的理想选择。
- 多模态交互:支持视觉、视频和音频能力,能够进行对象识别、语音识别以及文档/视频智能分析。
- 跨语言支持:预训练覆盖 140 多种语言,开箱即用支持 35 种以上语言。
开发者的新武器:AI 让生产力翻倍
不仅是底层模型的突破,AI 在软件开发实践中的应用也正经历着质的飞跃。以 RunSignup 为例,该公司预计到 2026 年底,通过全面采用 AI 开发工具,其每年的版本发布量将从 2000 个翻倍至 4000 个。

从“代码补全”到“AI 编写代码”
传统的 AI 辅助开发主要集中在代码补全(提升约 10-20% 效率),而现在的趋势是让 AI 根据开发者的“计划(Plan)”直接编写代码。开发者只需描述所需功能,AI(如 Claude 4.6 或 Gemma 4)就能生成完整的实现方案。通过建立名为“Skills”的知识库,开发者可以为 AI 提供特定系统的背景信息(如邮件系统、数据库架构),使 AI 生成的代码更具针对性和一致性。
智能体 AI (Agentic AI) 的实际应用
“智能体”不仅仅是一个流行语,它正在成为本地 PC 和企业工作流的核心。在 RTX PC 上,像 OpenClaw 这样的应用允许用户构建本地 Agent,利用个人文件和应用程序自动执行任务。
而在企业的开发流水线中,AI Agent 正在承担以下角色:
- 价值评估 Agent:通过分析业务逻辑和历史数据,自动评估功能请求的优先级。
- 代码审查 Agent:学习资深架构师的风格,在 GitHub 提交请求中自动提出改进建议。
- 自动化测试 Agent:编写并执行测试脚本,确保系统稳定性。

为什么硬件加速至关重要?
无论是运行 Gemma 4 还是复杂的开发 Agent,底层的算力支撑是关键。NVIDIA Tensor Cores 能够显著加速 AI 推理负载,为本地执行提供更高的吞吐量和更低的延迟。此外,CUDA 软件栈确保了模型在发布之初就能与各大框架(如 Ollama, llama.cpp)无缝兼容。
结语:拥抱 AI 驱动的变革
正如 RunSignup 所信奉的“积极的耐心(Aggressive Patience)”:我们必须积极地拥抱 AI,同时在执行过程中保持耐心,坚持人工审核每一行 AI 生成的代码。随着 AI 能力预计每 7 个月翻一倍,无论是个人用户还是企业,利用 RTX 加速的模型和智能体工具,将是保持竞争力的唯一途径。
未来的智能生活不仅在云端,更在触手可及的桌面端。