RTX 算力引爆:Google Gemma 4 系列模型加速迈向智能体 AI 新时代
随着开放模型的迅猛发展,端侧 AI 正在掀起新一轮创新浪潮。AI 的应用场景正从云端延伸至我们日常使用的各类设备。在这个转变过程中,AI 模型对于本地、实时上下文的访问能力变得至关重要。近日,Google 发布的 Gemma 4 系列模型正是为此而生。这一系列小型、高效且全能的模型,旨在跨多种设备实现极速的本地运行。
通过 Google 与 NVIDIA 的紧密合作,Gemma 4 已针对 NVIDIA GPU 进行了深度优化。无论是数据中心、搭载 NVIDIA RTX 的 PC、DGX Spark 个人 AI 超级计算机,还是 NVIDIA Jetson Orin Nano 边缘 AI 模块,都能流畅运行 Gemma 4,释放强大的生成式 AI 潜力。

Gemma 4:多尺寸模型赋能多样化场景
Gemma 4 系列涵盖了从 E2B、E4B 到 26B 和 31B 的多种参数规模。这种梯度式的设计确保了从轻量级边缘设备到高性能 GPU 都能找到最适合的部署方案:
- E2B & E4B 模型:专为超高效、低延迟的边缘推理设计,可在 Jetson Nano 等模块上完全离线运行,实现近乎零延迟的响应。
- 26B & 31B 模型:针对高性能推理和开发者工作流设计,非常适合构建复杂的智能体(Agent)和自动化流程。
核心能力概览
- 逻辑推理 (Reasoning):在处理复杂问题解决任务时表现出色。
- 代码编写 (Coding):支持开发者工作流中的代码生成与调试。
- 智能体支持 (Agents):原生支持结构化工具使用(函数调用),是构建本地 AI 助手的理想选择。
- 多模态交互:具备视觉、视频和音频处理能力,能够进行对象识别、自动语音识别以及文档/视频情报分析。
- 交错式输入:允许在单个提示词中以任何顺序混合文本和图像。
- 多语言支持:开箱即用支持 35+ 种语言,预训练数据集涵盖 140+ 种语言。
性能实测:NVIDIA RTX 的加速魅力
得益于 NVIDIA Tensor Cores 的硬件加速,Gemma 4 在 RTX GPU 上的表现令人瞩目。在量化测试中,GeForce RTX 5090 展示了极高的令牌生成吞吐量,能够轻松应对高负载的推理任务。
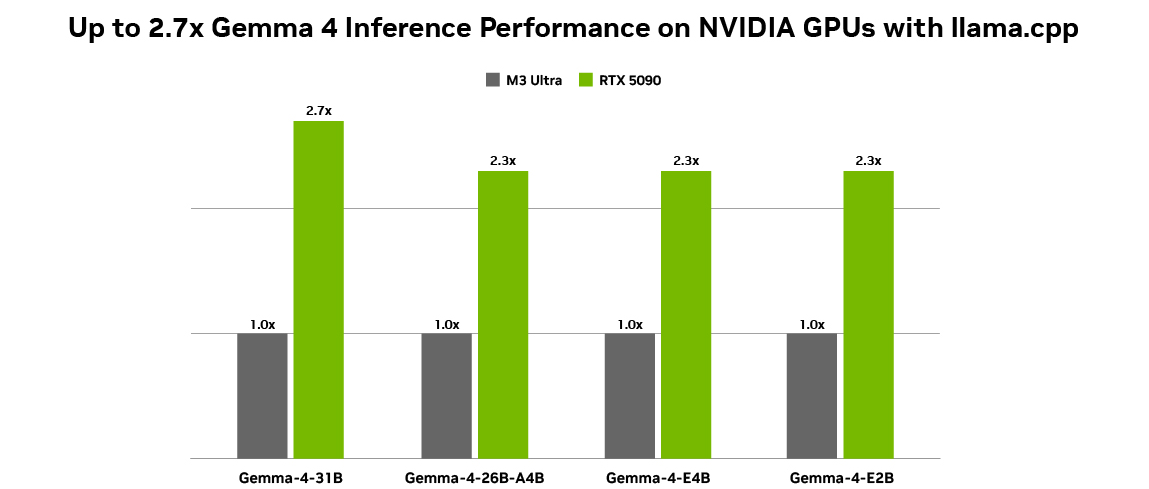
NVIDIA 的 CUDA 软件栈确保了与主流框架的广泛兼容性,这意味着开发者可以从第一天起就在 RTX 设备上高效运行新模型,无需进行繁琐的底层优化。
Agentic AI:开启个人自动化新篇章
本地智能体 AI(Local Agentic AI)正逐渐成为行业重心。像 OpenClaw 这样的应用正让 RTX PC 变身为 7x24 小时在线的 AI 助手。Gemma 4 与 OpenClaw 的完美兼容,允许用户构建能够理解个人文件、管理工作流并自动化复杂任务的本地智能体。
此外,NVIDIA 最近还推出了 NVIDIA NemoClaw,这是一个开源堆栈,通过增强安全性和本地模型支持,进一步优化了 NVIDIA 设备上的 OpenClaw 体验。
如何开始在 RTX 上使用 Gemma 4?
NVIDIA 与生态伙伴协作,提供了多种便捷的本地部署方式:
- Ollama:用户可以简单地下载 Ollama 并直接运行 Gemma 4 模型。
- llama.cpp:对于进阶用户,可以使用 llama.cpp 配合 Hugging Face 上的 GGUF 格式检查点进行部署。
- Unsloth:Unsloth Studio 提供首日支持,通过优化和量化技术,支持高效的本地微调(Fine-tuning)和部署。

总结
Google Gemma 4 与 NVIDIA RTX 的结合,标志着端侧 AI 进入了一个更加智能、响应更迅速的新阶段。无论你是希望在边缘侧实现实时视觉分析的硬件开发者,还是想要构建私密、高效个人 AI 助手的极客,Gemma 4 都提供了无与伦比的性能与灵活性。
随着更多像 Accomplish FREE 这样的零配置、私密化 AI 应用的出现,利用 RTX GPU 的算力,每个人的桌面都将成为一个强大的个人 AI 超级中心。